Timeline
Feb. 21, 2019, 6 a.m. UTC
July 1, 2019, 6 a.m. UTC
Challenge
Pose estimation of known uncooperative spacecraft plays an important role in various satellite servicing missions of scientific, economic, and societal benefits. For example, RemoveDEBRIS by Surrey Space Centre, Restore-L by NASA, Phoenix program by DARPA, and several missions planned by new space start-ups such as Effective Space Solutions and Infinite Orbits. Pose estimation enables debris removal technologies required for ensuring mankind’s continued access to space, refurbishment of expensive space assets, and the development of space depots to facilitate travel towards distant destinations.
In a nutshell

The goal of this challenge is to estimate the pose, i.e., the relative position and attitude, of a known spacecraft from individual grayscale images. The images were generated to capture a variety of poses and illumination conditions and are sourced from two complimentary testbeds to validate the domain adaptation and transferability of the proposed approaches.
... more
Prior demonstrations of pose estimation have utilized image processing based on hand-engineered features and/or a-priori coarse knowledge of the pose. However, these approaches are not scalable to spacecraft of different physical properties as well as not robust to the dynamic illumination conditions of space. Moreover, a-priori knowledge of the pose is not always available nor desirable when full autonomy is required. Recent advancements in machine learning provide promising alternatives, however, these suffer from unpredictable drops in performance when tested against images from a distribution not used during training. To overcome these limitations, the pose estimation challenge invites the community to propose and validate new approaches that make use of high fidelity images of the Tango spacecraft from the PRISMA mission. Launched in 2010, the PRISMA mission demonstrated close proximity operations between two spacecraft in low Earth orbit. Actual space imagery and associated flight dynamics products facilitated the generation of the images used in this challenge.
Due to the absence of public datasets relevant for space-borne applications, there is a dearth of common benchmarks to compare existing and new pose estimation techniques. Thus, the images and the associated pose information provided through this challenge provide an excellent gym to test and develop new ideas. With the recent successes that machine learning in general and deep learning in particular has had in many fields of image processing, we are happy to provide an opportunity to apply and benchmark new algorithms based on those techniques with more consolidated methodologies.
The dataset for this challenge was collected by the Space Rendezvous Laboratory (SLAB), and are part of SLAB’s Spacecraft PosE Estimation Dataset (SPEED) benchmark.
SLAB


SLAB conducts fundamental and applied research at the intersection of astrodynamics, navigation and control to enable future miniature distributed space systems. SLAB has made recent advancements in the domain of monocular vision-based pose estimation using feature-based methods [1] as well as deep-learning based methods [2, 3].
At SLAB, two key complementary facilities are used to conduct hardware-in-the-loop tests with representative vision-based cameras for space situational awareness and spacecraft proximity operations. The first facility is the Optical Stimulator (OS) [4]. The OS is a virtual reality testbed, which consists of a pair of actuated lenses that magnify a monitor. High-fidelity, synthetic scenes of the space environment are rendered to the monitor in real-time and closed-loop to stimulate a vision-based sensor test article.
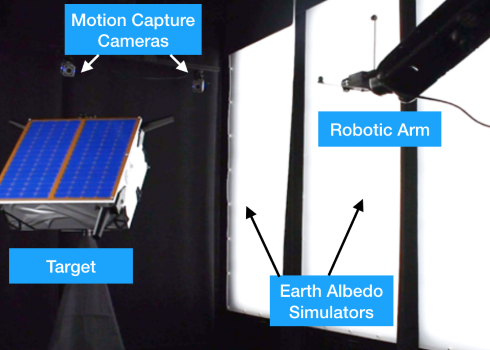
The second facility is the Testbed for Rendezvous and Optical Navigation (TRON). It consists of a 7 degrees-of-freedom robotic arm, which positions and orients a vision based sensor with respect to a target object or scene. Custom illumination devices simulate Earth albedo and Sun light to high fidelity to emulate the illumination conditions present in space.
Synthetic Images

The images are generated with SLAB's Optical Simulator [4], that uses a high fidelity texture model of the Tango spacecraft of the PRISMA mission [5,6] and the camera model of the Point Grey Grasshopper 3 camera with a Xenoplan 1.9/17mm lens (VBS). Gaussian blurring and white noise are added to all images to emulate the depth of field and shot noise, respectively. A portion of the images have a black background, simulating situations where the target is imaged against the star-field. The rest of the images have a background covered partially or fully by real images of the Earth.
Real images

The second source of the SPEED images is the TRON facility at SLAB. TRON provides images of a 1:1 mockup model of the Tango spacecraft of the PRISMA mission [5] using an actual Point Grey Grasshopper 3 camera with a Xenoplan 1.9/17mm lens. Note that this is the same camera as used in the OS camera emulator software. Calibrated motion capture cameras report the positions and attitudes of the camera and the Tango spacecraft, which are then used to calculate the “ground truth” pose of Tango with respect to the camera. While these images are used to evaluate the transferability of the submitted algorithms from synthetic to real images, the score calculated on these images is not used for ranking the submissions.
References
[1] Sharma S., Ventura, J., D’Amico S.; Robust Model-Based Monocular Pose Initialization for Noncooperative Spacecraft Rendezvous; Journal of Spacecraft and Rockets, Vol. 55, No. 6 (2018), pp. 1414-1429.
[2] Sharma S., Beierle C., D’Amico S.; Pose Estimation for Non-Cooperative Spacecraft Rendezvous Using Convolutional Neural Networks; IEEE Aerospace Conference, Yellowstone Conference Center, Big Sky, Montana, March 3-10 (2018).
[3] Sharma S., D'Amico S.; Pose Estimation for Non-Cooperative Rendezvous Using Neural Networks; 2019 AAS/AIAA Astrodynamics Specialist Conference, Ka'anapali, Maui, HI, January 13-17 (2019).
[4] Beierle C., D'Amico S.; Variable Magnification Optical Stimulator for Training and Validation of Spaceborne Vision-Based Navigation; Journal of Spacecraft and Rockets (2018). In Print.
[5] D’Amico S., Bodin P., Delpech M., Noteborn R.; PRISMA ; Chap 21, pp. 599-637. In: D'Errico M. (Ed.) Distributed Space Missions for Earth System Monitoring Space Technology Library, 2013, Volume 31, Part 4, 599-637. DOI 10.1007/978-1-4614-4541-8_21
[6] D’Amico S., Benn M., and Jørgensen J.L.; Pose Estimation of an Uncooperative Spacecraft from Actual Space Imagery; International Journal of Space Science and Engineering, Vol.2, No.2, pp.171 - 189 (2014). DOI: 10.1504/IJSPACESE.2014.060600